Generic AI is generic.
Useful AI knows your world.
- ▸ Anthropic, OpenAI, and Google are racing to make context the moat — by integrating your personal and enterprise data into their memory systems.
- ▸ The more useful they get, the harder it is to leave.
- ▸ This talk is about building that memory layer as yours instead.
What is OpenClaw?
Open Source · MITAn open-source agent runtime that connects chat, tools, memory, and automation into one self-hosted system. 378k+ GitHub stars · MIT licensed · runs entirely on your infrastructure.
One pipeline, three components
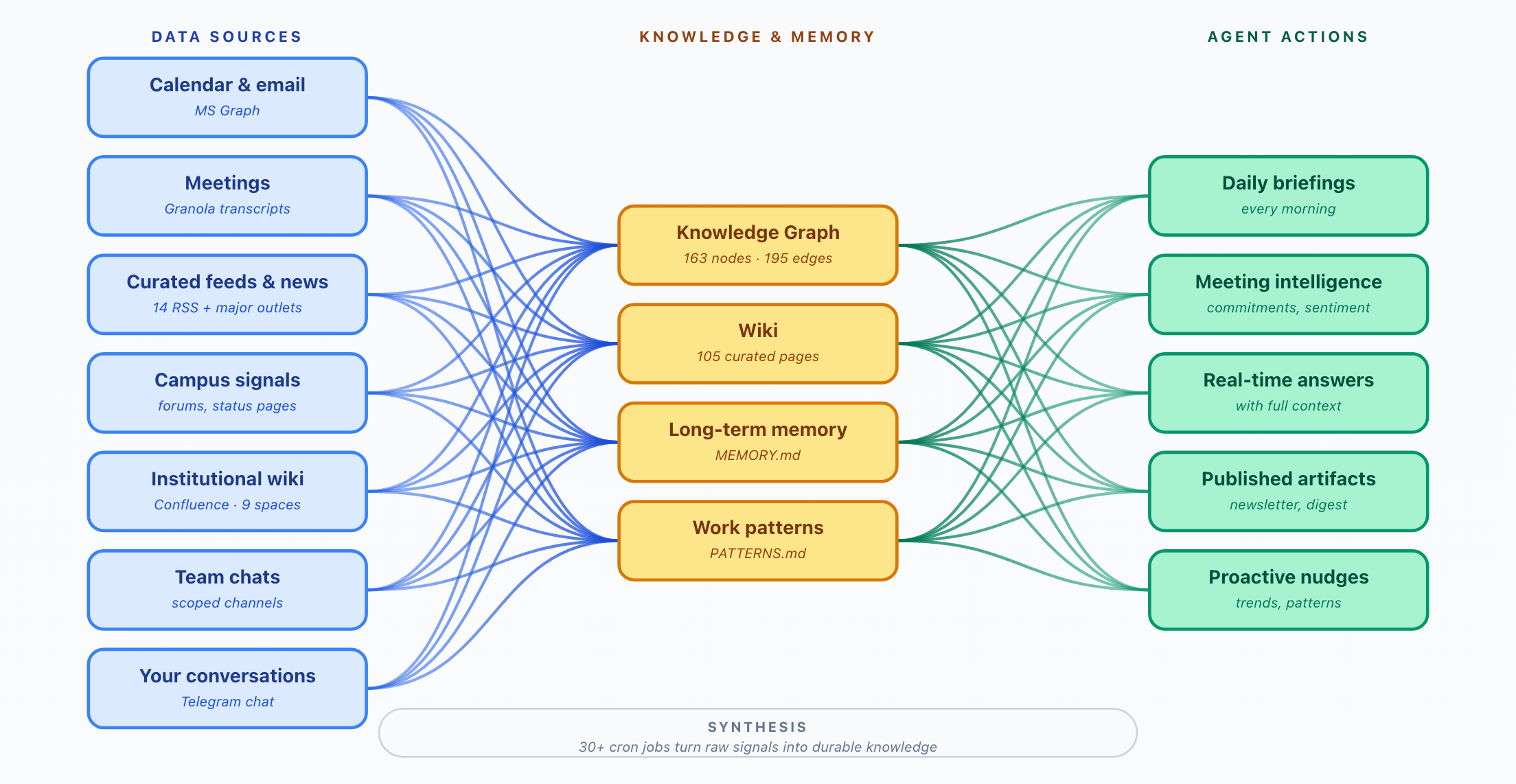
- Three components, one pipelineData sources → knowledge & memory → agent actions. Each piece is independently swappable.
- Knowledge is the moatMost personal-AI projects stop at “connect to email.” The interesting work is what comes next: capture, synthesize, retrieve.
- Synthesis is where the value lives78 cron jobs turn raw signals into durable knowledge — not just chat, a daily institutional memory build.
- Mission Control — the surface I work fromNext.js dashboard at mission-control.vercel.app. Cron outputs land as task cards, decisions queue for review, jobs report status. Telegram pushes the urgent; the dashboard holds the rest.
- Open formats, not vendor lockMarkdown + JSON on disk. Switch tools, keep your knowledge.
Three layers — and the one most personal AI projects skip
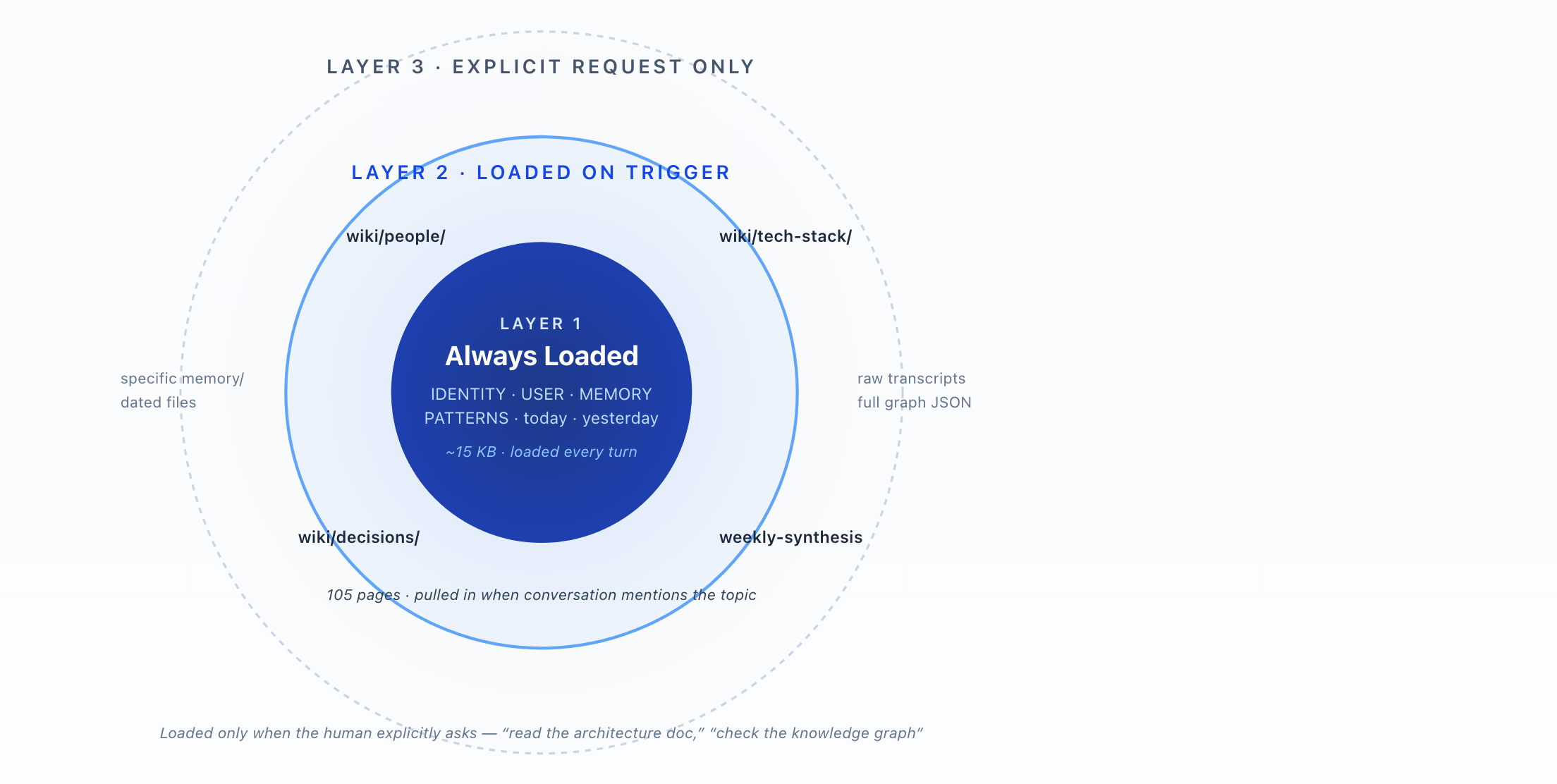
- Layer 1 — Always loaded (~15 KB)Identity, user profile, work patterns, today + yesterday. Cheap, fixed, every interaction.
- Layer 2 — Triggered (270 wiki pages)Mention a colleague → reads their wiki page. Mention a vendor → reads tech-stack page. The biggest unlock.
- Layer 3 — Explicit onlyFull transcripts, raw graph JSON, dated memory files. Rare deep-dives.
- Most projects skip Layer 2Without triggered retrieval, an accumulating wiki sits unused. The agent only knows what fits in the opening prompt.
78 cron jobs on a predictable daily rhythm
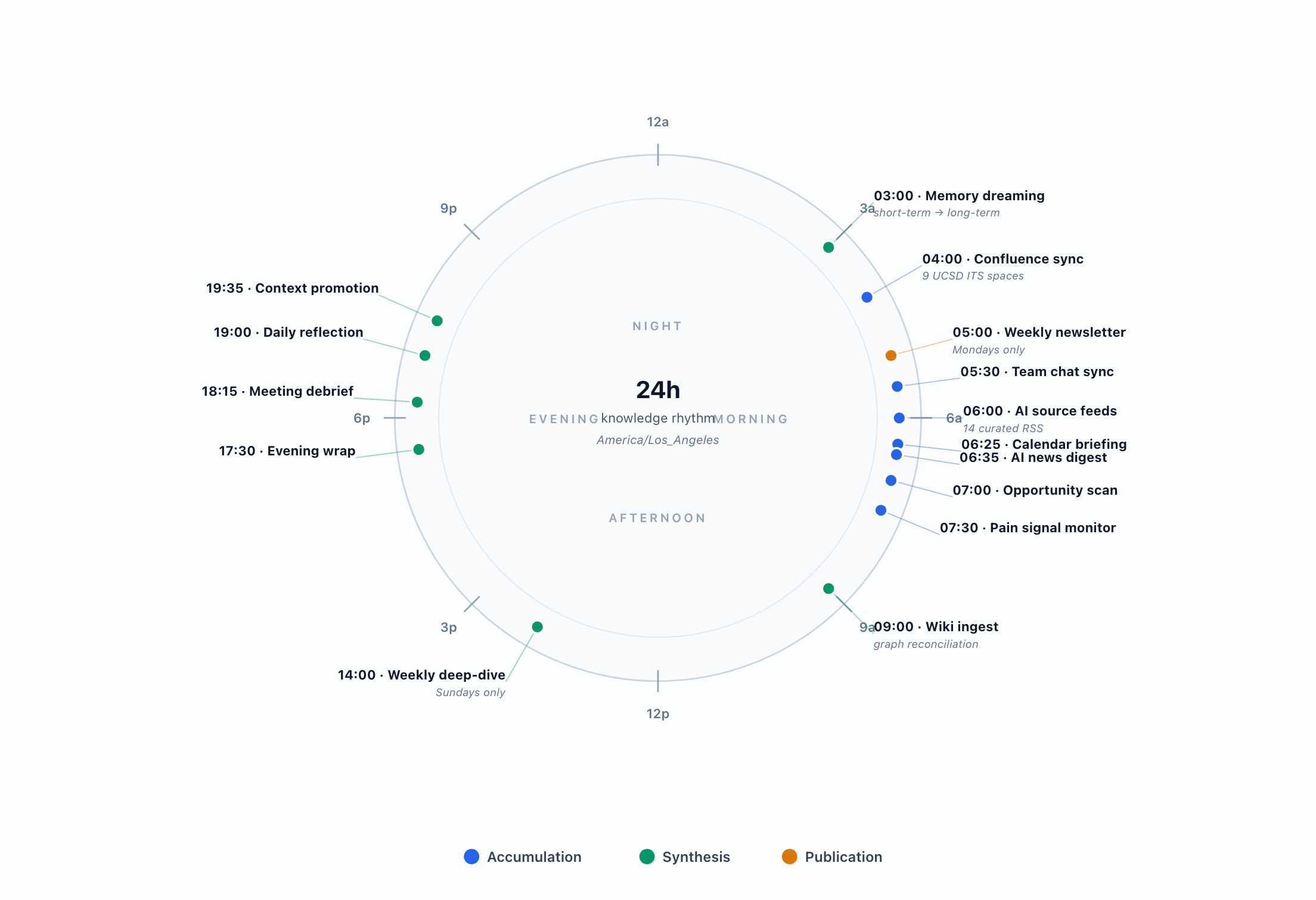
- 🌅 Morning (6–9 AM)Calendar briefing, AI news digest, opportunity scan, campus pain monitor, wiki ingest. Everything ready before I open a laptop.
- 🌆 Evening (5:30–7:35 PM)Email triage with drafts, meeting debrief, daily reflection, context promotion to long-term memory.
- 🌙 Night (3 AM)Memory consolidation — short-term → long-term, the way sleep does for humans.
- 📅 Weekly (Sunday)Cross-day pattern extraction. “VPN failed Mon, Wed, Fri” → “VPN is systemically broken this week.”
- The rhythm is the pipelineNot the individual jobs — the order they fire in is what turns raw files into institutional knowledge.
Six briefings before I open a laptop
• OpenAI quietly bumps GPT-5.5 reasoning — 2M context now default
• Anthropic ships MCP gateway updates relevant to your auth audit
• Google deprecates Gemma 3 (you migrated last week — no action)
brettcpollak.com/ai-digest ↗
Same items also queue as cards on Mission Control ↗ — Telegram for the urgent, the dashboard for the rest.
Model allocation — matching jobs to capabilities
All 69 active jobs run on TritonAI (UCSD’s institutional gateway, on-prem at SDSC) — zero vendor lock-in. 78 total configured, 9 disabled/deferred. 100% model-agnostic routing through TritonAI’s LiteLLM gateway.
| Tier | Alias | Provider · Model | Use & why this model fits | Jobs |
|---|---|---|---|---|
| Heavy agentic | gpt-oss-120b | TritonAI · OpenAI gpt-oss 120B | Briefings · opportunity scans · weekly signal synthesis · backlog triage · LinkedIn candidates — Best value: powerful single-shot reasoning at TritonAI open-source cost. Handles multi-step agentic work across the full pipeline. |
22 |
| Lightweight sync | mistral-small-3.2 | TritonAI · Mistral Small 3.2 | Token refresh · Gmail/Drive sync · confluence sync · disk watchdog · API health pings — Lowest latency on TritonAI, cheap per-call — perfect for stateless hygiene work that fires every 15-60 min. |
18 |
| Mid-tier synthesis | gemma-4 | TritonAI · Gemma 4 26B | Daily reflection · nightly context promotion · wiki ingest · team knowledge ops · evening wrap — Strong multimodal + 1M context window — handles synthesis, image understanding, and multi-source reasoning at low cost. |
16 |
| Long-form generation | mistral-large-3 | TritonAI · Mistral Large 3 675B | UCSD AI newsletter · LinkedIn post drafts · architecture reviews · vision tracking — Best narrative flow on TritonAI — preserves voice across long-form prose without sounding generic. |
6 |
| Deep reasoning | sonnet | TritonAI · Claude Sonnet 4.6 | Email triage · weekly AI deep-dive · identity drift review · provider quota monitoring — Reserved for jobs that need careful analysis, multi-source verification, and nuanced judgment — worth the premium for low-frequency high-stakes work. |
5 |
| Specialized code | deepseek-v4 | TritonAI · DeepSeek V4 Flash Max | Overnight code maintenance — Code-specific reasoning that handles refactoring, dependency updates, and repo hygiene without drift. |
1 |
| Health check | gpt-oss-120b | TritonAI · OpenAI gpt-oss 120B | Henry API health ping — Same model as heavy agentic tier; just a single hourly status check that doesn’t need its own category. |
1 |
| System default | default | TritonAI · DeepSeek V4 Flash Max | Feature reminder — Unpinned job inherits the system default model. One catch-all that keeps complexity low. |
1 |
Same 69 active jobs, three pricing scenarios
Read each column top-to-bottom — vendor totals up top, then how Core memory and Brett-specific jobs break down underneath.
On-prem open-weight models on UCSD GPUs at SDSC have ~$0/mo marginal cost (sunk institutional infra). TritonAI column uses actual published API rates from model_hub_table as of June 2026. Comparison columns use published Anthropic/OpenAI API rates on the same estimated token consumption. Core vs Brett-specific split estimated from job allocation patterns.
What the system actually delivers
Scaling to UC San Diego — what if every staff member had one?

- 1 · Personal — own agent, own dataProven daily. Every staff member gets dedicated runtime, isolated data store, governance default of “this is yours.”
- 2 · Team — opt-in sharing onlyTeam wiki visible to members; 1:1s and personal notes stay private. Nothing crosses the boundary automatically.
- 3 · Department — anonymized aggregates“Trending pain points this week” — patterns from many agents, not records. Identity stripped before aggregation.
- 4 · Campus — statistical patterns onlyConnective tissue across departments. Never individual records, never attributable content.
- 🛡️ Privacy is the preconditionSharing boundaries are first-class features, not bolt-ons. Without that guarantee at every level, nothing ships.